Un tema candente últimamente es si debemos bloquear los bots que de empresas IA que están recopilando información de todo internet para entrenar sus modelos. Mi opinión personal en estos momentos es que sí, sobre todo, después de algunas declaraciones incendiarias de algún ejecutivo indicando que si está publicado en internet es de uso libre. Puede que sí, pero por lo menos queremos que nuestro trabajo reciba cierta atribución, que reciba tráfico web… algo…
Vamos a verlo al revés: ¿Qué pasa si yo empiezo a hacer scraping web de Google, Amazon o Microsoft? Que no les mola nada y lo van a impedir de mil maneras diferentes. Parece que en ese caso la información no es libre, aunque este en internet. Solo funciona en un sentido. No es justo.
Por eso, te voy a comentar como evitar que los AI Bots, o AI crawlers se lleven la información de tu web. Y no va a ser publicando un inocente archivo robots.txt, qué muchas veces se pasan por el forro.
Vas a poder evitar que bots como ClaudeBot, GPTBot, GoogleOther, AmazonBot se lleven la información de tu web sin dar nada a cambio. ¿Cómo? Pues primero te voy a contar cómo hacerlo con Cloudflare de varias maneras, y luego con el archivo .htaccess de tu servidor Apache. Pero también como evitar que analicen tu web empresas SEO.
¿Por qué deberías de bloquear la mayoría de los bots?
Por muchas razones: La primera es que muchos se llevan tu información, esa que tanto te ha costado publicar sin darte nada a cambio. La segunda es que gastan el ancho de banda, la RAM y la CPU de tu servidor. Y eso es dinero. Y luego usan tu información para entrenar LLM (Modelos de Lenguaje). Y las empresas SEO, cuentan todos tus secretos a tus competidores. Por lo menos que visiten personalmente tu web… y que luego actúen en consecuencia.
¿Cómo se suelen bloquear? De tres maneras:
- Mediante Robots.txt (unas reglas que los buenos bots suelen seguir pero que los malos no).
- Bloqueándolos en tu servidor mediante reglas, por ejemplo en Apache con reglas en .htaccess.
- Bloqueándolos en Firewalls online como Cloudflare.
Cómo bloquear los bots AI con Cloudflare
Tienes que gestionar el DNS de tu Dominio con Cloudflare para que funcione este método. Es gratis y sencillo de implementar.
En esta página de Cloudflare tiene un listado de todos los bots verificados. Es interesante conocerla porque están distribuidos en categorías y gracias a eso puedes bloquear la categoría especifica que quieras.
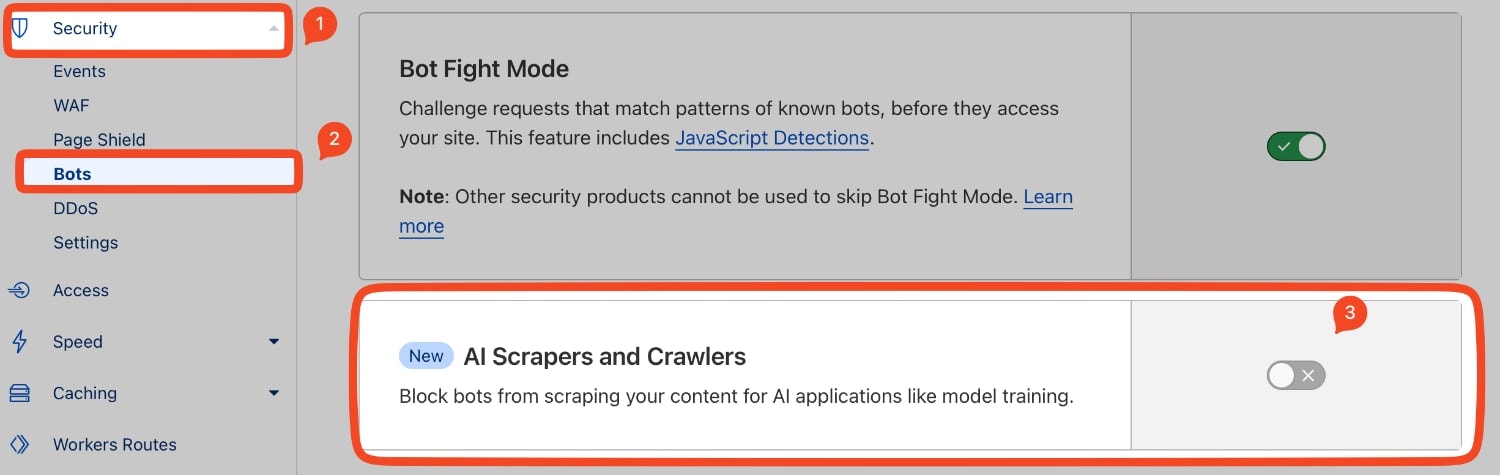
Si ya tienes tu dominio configurado en Cloudflare, solo tienes que ir a Security > Bots y activar AI Scrapers and Crawlers para activar una regla en su WAF que bloquea a estos bots. En este momento, vas a bloquear a ClaudeBot, GPTBot, GoogleOther, AmazonBot si activas esta pestaña.
¿Por qué no lo tengo activado yo? En esta sección tengo activado Bot Fight Mode, que bloquea todo tipo de robots malos, pero para bloquear a los bots AI, he creado una regla muy especial en Security > WAF:
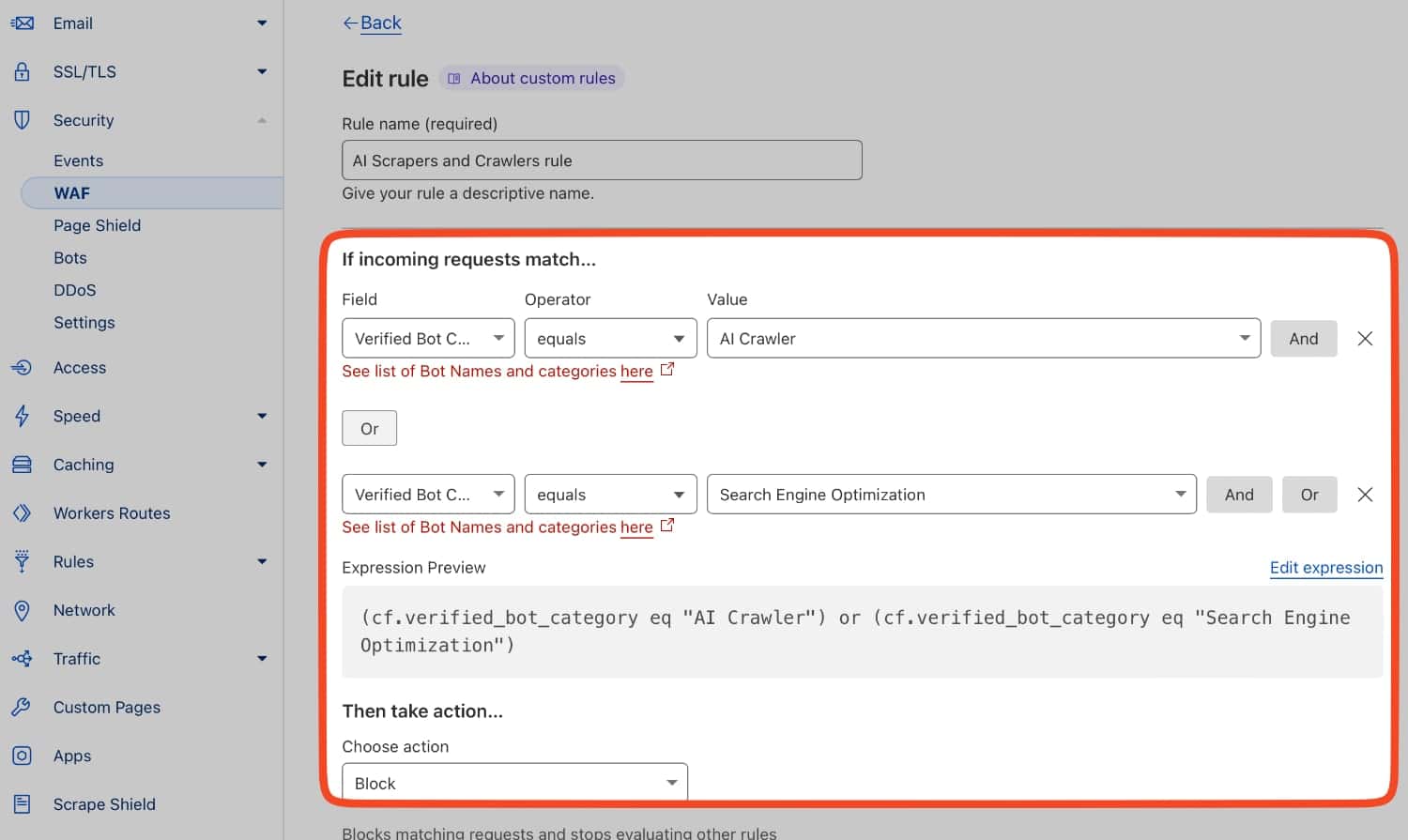
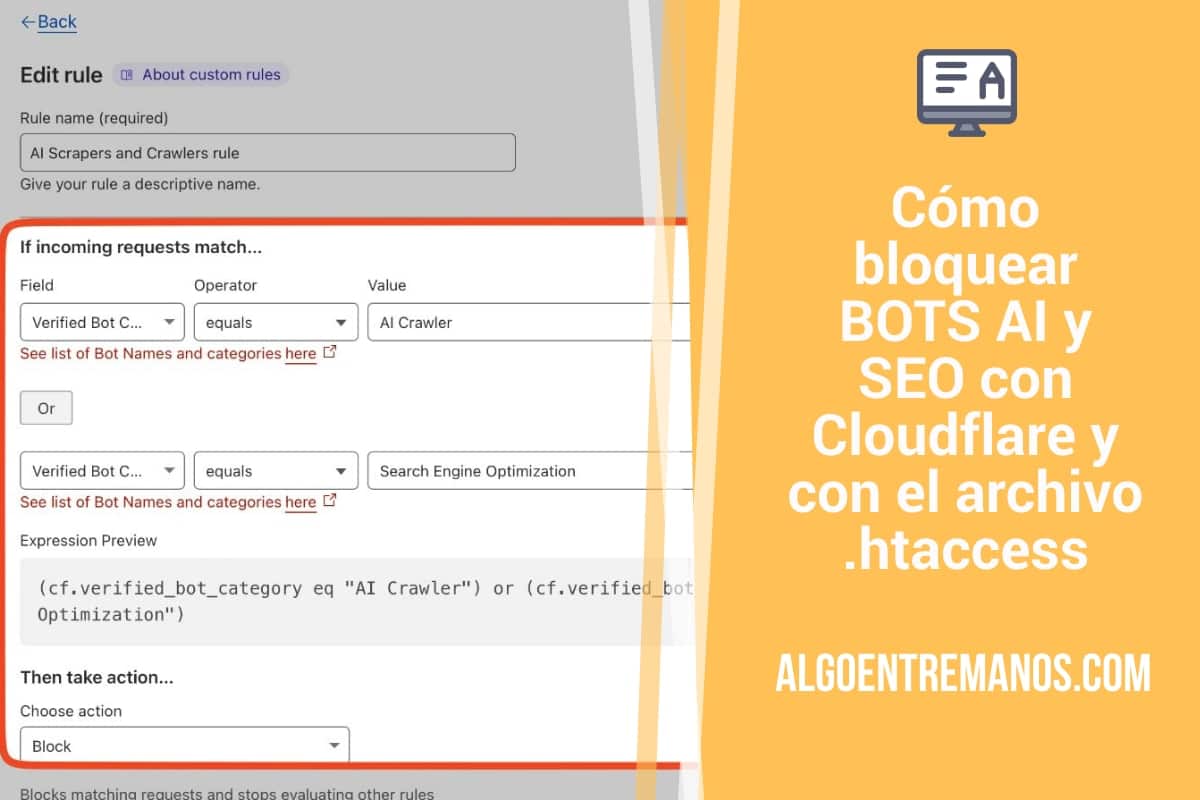
He puesto lo siguiente en la regla:
(cf.verified_bot_category eq "AI Crawler") or (cf.verified_bot_category eq "Search Engine Optimization")Además, de poner los bots AI, también he puesto los bots SEO que visitan nuestras webs. Bots de empresas como SEMrush, AHREFS y demás. Están todos en la categoría de Cloudflare Search Engine Optimization.
¿Más categorías que tienes en Cloudflare? Puedes ir añadiendo más cosas a tus reglas dle WAF.
- Search Engine Crawler,
- Aggregator,
- AI Crawler,
- Page Preview,
- Advertising
- Academic Research,
- Accessibility,
- Feed Fetcher,
- Security,
- Webhooks.
¿Acción a tomar? Pones Block. No te andas con contemplaciones. Y en las últimas 24 horas fíjate la cantidad de visitas que ha bloqueado Cloudflare:

Te recuerdo, que además de poner esta regla, puedes añadir tus propias reglas para bloquear Bots mediante User Agents y también puedes implementar medidas con un Firewall como CSF en tu servidor. Solo tienes que saber le nombre de usar Agent del bot y poner una regla como esta:
(http.user_agent contains "Bytespider") or (http.user_agent contains "FacebookBot")Y como acción, bloquear o un buen Managed Challenge. Te lo he contado todo en entradas anteriores. Tienes más control sobre lo que estás haciendo, pero si cambia el User Agent, estás perdido. Con el ejemplo de este post, lo dejas todo en manos de Cloudflare.
¡Truco! ¿Dónde puedes consultar los nombre de User Agents de estos robots? En https://darkvisitors.com/agents.
¿Es infalible este método? Pues probablemente no, pero es como siempre, un juego entre un gato y un ratón. A veces los cazas, a veces no.
En tus propias reglas mediante User Agents, puedes valorar poner los siguientes:
| Crawler AI | Descripción |
|---|---|
| Anthropic-ai | Anthropic-ai es un crawler operado por Anthropic para recopilar datos para sus LLMs como Claude. |
| Bytespider | Bytespider es un web crawler operado por ByteDance, el propietario chino de TikTok. Los datos se utilizan para entrenar sus LLMs, incluidos los que impulsan el competidor de ChatGPT, Doubao. |
| CCBot | CCBot es un web crawler utilizado por Common Crawl. Con sede en Europa, Common Crawl ha pasado años recopilando grandes cantidades de datos de la web y organizando los conjuntos de datos para LLMs. |
| ChatGPT-User | ChatGPT-User no es un web crawler, sino un bot que los plugins de ChatGPT utilizan para acceder a tu sitio web. |
| FacebookBot | FacebookBot es otro crawler que recopila datos de Internet para entrenar los LLMs de Meta. |
| FriendlyCrawler | FriendlyCrawler es un nuevo scraper web que utiliza sistemas autónomos de Amazon (AWS) y aparentemente recopila datos para «experimentos de aprendizaje automático». |
| Google-Extended | Google-Extended es el user agent asignado a los crawlers que recopilan datos para los LLMs de Google, como Gemini. |
| GPTBot | GPTBot es el web crawler de OpenAI que recopila datos para entrenar su modelo de lenguaje grande (LLM). |
| Image2dataset | Image2dataset es una herramienta scraper que las personas pueden usar para recopilar URLs de imágenes. Las URLs se utilizan en conjuntos de datos para LLMs. |
| ImagesiftBot | ImageSiftBot es un web crawler que recopila imágenes disponibles públicamente. Es propiedad de Hive, que también ofrece una IA de generación de imágenes. |
| Omgilibot | Omgilibot es un web scraper de webz.io. Los datos de la recopilación se utilizan para alimentar su índice, que venden para el entrenamiento de LLMs. |
| PerplexityBot | PerplexityBot es un web scraper utilizado por Perplexity AI, un motor de búsqueda alternativo. |
| Crawler SEO | Descripción |
|---|---|
| AhrefsBot | Es un crawler de Ahrefs que recopila datos SEO de tu sitio web y los vende a tus competidores para que puedan superarte en los motores de búsqueda. |
| Barkrowler | Es un crawler SEO de Babbar.tech, que alimenta su representación gráfica de la web y ofrece herramientas de marketing en línea para agencias SEO. |
| BLEXBot | BLEXBot ayuda a los vendedores en línea a obtener información sobre la estructura de enlaces de los sitios y mejorar la experiencia en línea. |
| DataForSeoBot | Es un bot verificador de backlinks que recopila información SEO de tu sitio web y la vende a clientes. |
| DotBot | Es un crawler de backlinks de Moz. Si no utilizas estos servicios, no hay razón para proporcionar esta información a tu competidor. |
| MJ12Bot | Es un crawler que recopila datos SEO para la empresa Majestic. |
| SemrushBot | Operado por Semrush, un competidor de Ahrefs. Bloquéalo si no utilizas sus servicios. |
Cómo puedes bloquear estos BOTS AI y SEO desde tu servidor
Esto es un poco más técnico, pero no mucho más difícil de implementar. Te recomiendo utilizar parte del código del Firewall de Perishable Press, que va por su versión 8G. La sección interesante es la de # 8G:[USER AGENT]
# 8G FIREWALL v1.3 20240222
# https://perishablepress.com/8g-firewall/
# 8G:[USER AGENT]
<IfModule mod_rewrite.c>
RewriteCond %{HTTP_USER_AGENT} ([a-z0-9]{2000,}) [NC,OR]
RewriteCond %{HTTP_USER_AGENT} (<|%0a|%0d|%27|%3c|%3e|%00|0x00|\\\x22) [NC,OR]
RewriteCond %{HTTP_USER_AGENT} (ahrefs|archiver|curl|libwww-perl|pycurl|scan) [NC,OR]
RewriteCond %{HTTP_USER_AGENT} (oppo\sa33|(c99|php|web)shell|site((.){0,2})copier) [NC,OR]
RewriteCond %{HTTP_USER_AGENT} (base64_decode|bin/bash|disconnect|eval|unserializ) [NC,OR]
RewriteCond %{HTTP_USER_AGENT} (acapbot|acoonbot|alexibot|asterias|attackbot|awario|backdor|becomebot|binlar|blackwidow|blekkobot|blex|blowfish|bullseye|bunnys|butterfly|careerbot|casper) [NC,OR]
RewriteCond %{HTTP_USER_AGENT} (checkpriv|cheesebot|cherrypick|chinaclaw|choppy|clshttp|cmsworld|copernic|copyrightcheck|cosmos|crescent|datacha|(\b)demon(\b)|diavol|discobot|dittospyder) [NC,OR]
RewriteCond %{HTTP_USER_AGENT} (dotbot|dotnetdotcom|dumbot|econtext|emailcollector|emailsiphon|emailwolf|eolasbot|eventures|extract|eyenetie|feedfinder|flaming|flashget|flicky|foobot|fuck) [NC,OR]
RewriteCond %{HTTP_USER_AGENT} (g00g1e|getright|gigabot|go-ahead-got|gozilla|grabnet|grafula|harvest|heritrix|httracks?|icarus6j|jetbot|jetcar|jikespider|kmccrew|leechftp|libweb|liebaofast) [NC,OR]
RewriteCond %{HTTP_USER_AGENT} (linkscan|linkwalker|loader|lwp-download|majestic|masscan|miner|mechanize|mj12bot|morfeus|moveoverbot|netmechanic|netspider|nicerspro|nikto|ninja|nominet|nutch) [NC,OR]
RewriteCond %{HTTP_USER_AGENT} (octopus|pagegrabber|petalbot|planetwork|postrank|proximic|purebot|queryn|queryseeker|radian6|radiation|realdownload|remoteview|rogerbot|scan|scooter|seekerspid) [NC,OR]
RewriteCond %{HTTP_USER_AGENT} (semalt|siclab|sindice|sistrix|sitebot|siteexplorer|sitesnagger|skygrid|smartdownload|snoopy|sosospider|spankbot|spbot|sqlmap|stackrambler|stripper|sucker|surftbot) [NC,OR]
RewriteCond %{HTTP_USER_AGENT} (sux0r|suzukacz|suzuran|takeout|teleport|telesoft|true_robots|turingos|turnit|vampire|vikspider|voideye|webleacher|webreaper|webstripper|webvac|webviewer|webwhacker) [NC,OR]
RewriteCond %{HTTP_USER_AGENT} (winhttp|wwwoffle|woxbot|xaldon|xxxyy|yamanalab|yioopbot|youda|zeus|zmeu|zune|zyborg) [NC]
RewriteRule .* - [F]
# RewriteRule .* /nG_log.php?log [END,NE,E=nG_USER_AGENT:%1]
</IfModule>Puedes usar solo la parte que te interese. Lo importante es que tienes la base para ir poniendo los nombres de USER AGENTS que te interese bloquear en tu servidor. Es decir, puedes poner algo como esto:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (acapbot|acoonbot|alexibot|asterias|attackbot|awario|backdor|becomebot|binlar|blackwidow|blekkobot|blex|blowfish|bullseye|bunnys|butterfly|careerbot|casper|checkpriv|cheesebot|cherrypick|chinaclaw|choppy|clshttp|cmsworld|copernic|copyrightcheck|cosmos|crescent|datacha|demon|diavol|discobot|dittospyder) [NC]
RewriteRule .* - [F]
</IfModule>- RewriteEngine On: Asegura que el motor de reescritura esté activado.
- RewriteCond %{HTTP_USER_AGENT} … [NC]: Verifica si el User-Agent de la solicitud coincide con cualquiera de los bots listados, sin distinguir entre mayúsculas y minúsculas.
- RewriteRule . – [F]*: Si se cumple alguna de las condiciones, la solicitud se bloquea con un estado HTTP 403 (Forbidden).
Puedes cambiar el nombre de los USER AGENTS a tu gusto o puedes dejar los que te recomiendan en esta web. Personalmente, te recomiendo que los elijas tú mismo y que pongas los bots AI y SEO que te he nombrado antes. Tienes que comprobar que tienes activado el módulo mod_rewrite en Apache y luego poner este código en tu archivo .htaccess en la raíz de tu sitio web.
Conclusión
Combinando estas dos aproximaciones (y si quieres el archivo robots.txt), estás haciéndote un gran favor a ti y a tu web. Estás evitando que se lleven tu contenido sin darte nada a cambio. Por lo menos que te pongan un link y te envíen tráfico, ¿no?
